 Information about the Apollo CPU and FPU. Information about the Apollo CPU and FPU. |
|
|---|
| | 
Grom 68k
Posts 61
16 Jul 2019 10:29
| This is an other example which work better than last week but there is still a problem:
void multiplyMatrix(double* restrict inputMatrix,double transformMatrix[4][4],double* restrict outputMatrix)
{
for(int i = 0; i < 4; i++ ){
outputMatrix = 0;
for(int j = 0; j < 4; j++){
outputMatrix += transformMatrix[j] * inputMatrix[j];
}
}
}
gcc use an unnessecary fp2 to init (a2): -m68080 -O2 -mregparm=3
_multiplyMatrix:
moveq #4,d1
fmovem fp2,-(sp)
fmove.s #0x0,fp2
movem.l a4/a3/a2,-(sp)
.L3:
fmove.d #0x000000000,fp0
fmove.d fp2,(a2)
move.l a0,a4
move.l a1,a3
moveq #4,d0
.L2:
fdmove.d (a3)+,fp1
fdmul.d (a4)+,fp1
fdadd.x fp1,fp0
subq.l #1,d0
jne .L2
fmove.d fp0,(a2)+
lea (32,a1),a1
subq.l #1,d1
jne .L3
movem.l (sp)+,a2/a3/a4
fmovem (sp)+,fp2
rts
with -O3, it's worse, i add 0 to fp1 -m68080 -O3 -mregparm=3
fdadd.d #0x000000000,fp1
| |
| | 
Samuel Devulder
Posts 248
16 Jul 2019 11:10
| The C-code is strange. OutputMatrix is used as a double, but it is a pointer. The 'i' index isn't used as index either, which is weird. What is this function supposed to do? Mulitply 4x4 matrices or multiply a vector by a matrix ?
| |
| |
Grom 68k
Posts 61
16 Jul 2019 11:21
| Samuel Devulder wrote:
|
The C-code is strange. OutputMatrix is used as a double, but it is a pointer. The 'i' index isn't used as index either, which is weird. What is this function supposed to do? Mulitply 4x4 matrices or multiply a vector by a matrix ?
|
Thanks, I discover the italic tag. This is better like this:
void multiplyMatrix(double* restrict inputMatrix,double transformMatrix[4][4],double* restrict outputMatrix)
{
for(int l = 0; l < 4; l++ ){
outputMatrix[l] = 0;
for(int j = 0; j < 4; j++){
outputMatrix[l] += transformMatrix[l][j] * inputMatrix[j];
}
}
}
It multiplies vector by a matrix to make a rotation and a translation. I use this in CAD program.
I write before double outputMatrix[4] but it's better with restrict.
| |
| | 
Stefan "Bebbo" Franke
Posts 142
16 Jul 2019 11:50
| a zip with all is ok.
regarding that code: I'm not sure if it's allowed to suppress the explicite coded zero assignment. I recommend fixing the c code and use a local variable to sum it up and only store the result.
EDIT: hint: use [ code] for your code
LOL: hard to format this
| |
| |
Samuel Devulder
Posts 248
16 Jul 2019 13:01
| There are strange things occuring with this matrix*vector routine. EXTERNAL LINK There are lots of "fadd #0,freg" as pointed out by Grom68k, and even, what looks like bad scheduling when unrolling all the loops:
fdmul.x fp2,fp1
fdadd.d #0x000000000,fp1 ; useless & waits for fp1 during 5 cycles
...
fdmul.x fp0,fp3
fdmove.x fp2,fp4
fdmul.d (16,a1),fp4
fdadd.x fp1,fp3 ; has to wait 2 cycles for fp3
...
fdmul.x fp6,fp5
fdadd.x fp5,fp3 ; has to wait 5 cycles for fp5
...
fdmul.d (16,a1),fp3
fdadd.d #0x000000000,fp4 ; useless
fdadd.d #0x000000000,fp1 ; useless
fdadd.x fp3,fp7 ; has to wait 3 cycles for fp3
...
fdmul.d (56,a1),fp0
fdmul.d (88,a1),fp2
fdadd.x fp0,fp4 ; wait 4 cycles for fp0
fdadd.x fp1,fp2 ; wait 1 cycle for fp2 (4 already used before.)
...
Strangely enough, when rewriting the C code to invert the order of the l/j loops, the resulting asm looks a bit better (no fadd #0) EXTERNAL LINK
[EDIT] adding -funsafe-math-optimizations (or -ffast-math which includes it) removes the useless "fadd #0" as well, but scheduling seem still bad.
fdmove.d (8,a1),fp3
fdmul.x fp4,fp3
fdmul.x fp2,fp1
fdadd.x fp3,fp1 ; <== has to wait for fp1 & fp3 (5 wait-ycles)
[EDIT2] Playing with "-Ofast -mregpam" lead to a compiler crash ==> EXTERNAL LINK
This piece of c-code is, I think, very good to check scheduling performance & limitations. I wonder if hand-written asm can beat gcc.
| |
| |
Grom 68k
Posts 61
16 Jul 2019 16:57
| Samuel Devulder wrote:
|
This piece of c-code is, I think, very good to check scheduling performance & limitations. I wonder if hand-written asm can beat gcc.
|
I think this code is easier to start to check scheduling.
void crossproduct(const double* restrict vector1, const double* vector2, double* restrict vector3)
{
double v10 = *vector1++;
double v11 = *vector1++;
double v12 = *vector1;
double v20 = *vector2++;
double v21 = *vector2++;
double v22 = *vector2;
*vector3++ = v11 * v22 - v12 * v21;
*vector3++ = v12 * v20 - v10 * v22;
*vector3 = v10 * v21 - v11 * v20;
}
| |
| |
Stefan "Bebbo" Franke
Posts 142
16 Jul 2019 21:28
| Grom 68k wrote:
|
Samuel Devulder wrote:
|
This piece of c-code is, I think, very good to check scheduling performance & limitations. I wonder if hand-written asm can beat gcc.
|
I think this code is easier to start to check scheduling.
void crossproduct(const double* restrict vector1, const double* vector2, double* restrict vector3)
{
double v10 = *vector1++;
double v11 = *vector1++;
double v12 = *vector1;
double v20 = *vector2++;
double v21 = *vector2++;
double v22 = *vector2;
*vector3++ = v11 * v22 - v12 * v21;
*vector3++ = v12 * v20 - v10 * v22;
*vector3 = v10 * v21 - v11 * v20;
}
|
13 wait states are ok for me - not bad for an algorithm.
| |
| |
Samuel Devulder
Posts 248
16 Jul 2019 23:58
| I count only 9 here: EXTERNAL LINK
_crossproduct:
fdmove.d (a0)+,fp0
fmovem fp2/fp3/fp4/fp5/fp6/fp7,-(sp)
fdmove.d (a0)+,fp1
fdmove.d (a1)+,fp3
fdmove.d (a0),fp6
fdmove.d (a1)+,fp2
fdmove.x fp1,fp5
fdmove.d (a1),fp4
fdmove.x fp6,fp7
fdmul.x fp4,fp5
fdmul.x fp2,fp7
fdmul.x fp0,fp4
fdmul.x fp3,fp6
; 3 because of fp7
fdsub.x fp7,fp5
fdmul.x fp2,fp0
fdmul.x fp3,fp1
; no wait state for fp4/fp6 because of 3 above
fdsub.x fp4,fp6
; 4 because of fp1
fdsub.x fp1,fp0
move.l d0,a0
fmove.d fp5,(a0)+
fmove.d fp6,(a0)+
; 2 because of fp0
fmove.d fp0,(a0)
fmovem (sp)+,fp7/fp6/fp5/fp4/fp3/fp2
rts
If we manually reorg we can get even fewer (4):
_crossproduct:
fdmove.d (a0)+,fp0
fmovem fp2/fp3/fp4/fp5/fp6/fp7,-(sp)
fdmove.d (a0)+,fp1
fdmove.d (a1)+,fp3
fdmove.d (a0),fp6
fdmove.d (a1)+,fp2
fdmove.x fp1,fp5
fdmove.d (a1),fp4
fdmove.x fp6,fp7
fdmul.x fp4,fp5
fdmul.x fp2,fp7
fdmul.x fp0,fp4
fdmul.x fp3,fp6
fdmul.x fp2,fp0
fdmul.x fp3,fp1
; 1 because of fp7
fdsub.x fp7,fp5
; 1 because of fp6
fdsub.x fp4,fp6
move.l d0,a0
fdsub.x fp1,fp0
; 1 because of dfp5
fmove.d fp5,(a0)+
; 1 because of fp6
fmove.d fp6,(a0)+
fmovem (sp)+,fp7/fp6/fp5/fp4/fp3/fp2
fmove.d fp0,(a0)
rts
| |
| |
Stefan "Bebbo" Franke
Posts 142
17 Jul 2019 07:20
| Samuel Devulder wrote:
|
I count only 9 here: EXTERNAL LINK
...
If we manually reorg we can get even fewer (4):
...
|
I tweaked it a bit, but that's it. It's easy to unbalance the weights and get worse results. So 9 is better than 13 before :-) If you are able to define the algorithm of your 'manual reorg', it might be worth to implement it.
| |
| | 
Gunnar von Boehn
(Apollo Team Member)
Posts 6243
17 Jul 2019 07:27
| Stefan "Bebbo" Franke wrote:
|
Samuel Devulder wrote:
|
I count only 9 here: EXTERNAL LINK
...
If we manually reorg we can get even fewer (4):
...
|
I tweaked it a bit, but that's it. It's easy to unbalance the weights and get worse results. So 9 is better than 13 before :-)
If you are able to define the algorithm of your 'manual reorg', it might be worth to implement it.
|
I see several optimizations here which sometimes might conflict.
a) Make GCC be aware of the latency
6 cycle for FADD/FSUB/FCMP/FMUL
b) bundle "FMOVE and FOPP" to one unit.
This can allow the CPU to execute both together!
In general the 68080 CPU can reach great FPU speed for bigger workloops which are unrolled.
Like the "SCALE" over a bigger amount of data.
I believe our focus should be on such algorithms.
Algorithms with are more "sequential" are a lost cause anyhow.
| |
| |
Stefan "Bebbo" Franke
Posts 142
17 Jul 2019 08:28
| I created a better m68080 automaton definition
_crossproduct:
fdmove.d (a0)+,fp0
fmovem fp2/fp3/fp4/fp5/fp6/fp7,-(sp)
fdmove.d (a0)+,fp1
fdmove.d (a1)+,fp3
fdmove.d (a1)+,fp2
fdmove.d (a0),fp6
fdmove.x fp1,fp5
fdmove.d (a1),fp4
fdmove.x fp6,fp7
fdmul.x fp4,fp5
fdmul.x fp2,fp7
fdmul.x fp0,fp4
fdmul.x fp3,fp6
fdmul.x fp2,fp0
fdmul.x fp3,fp1
move.l a2,-(sp)
fdsub.x fp7,fp5
fdsub.x fp4,fp6
fdsub.x fp1,fp0
fmove.d fp5,(a2)+
fmove.d fp6,(a2)+
fmove.d fp0,(a2)
move.l (sp)+,a2
fmovem (sp)+,fp7/fp6/fp5/fp4/fp3/fp2
rts
it's 4 too, isn't it?
| |
| |
Gunnar von Boehn
(Apollo Team Member)
Posts 6243
17 Jul 2019 08:42
| Stefan "Bebbo" Franke wrote:
|
I created a better m68080 automaton definition
_crossproduct:
fdmove.d (a0)+,fp0
fmovem fp2/fp3/fp4/fp5/fp6/fp7,-(sp)
fdmove.d (a0)+,fp1
fdmove.d (a1)+,fp3
fdmove.d (a1)+,fp2
fdmove.d (a0),fp6
fdmove.x fp1,fp5 (1)
fdmove.d (a1),fp4
fdmove.x fp6,fp7 (2)
fdmul.x fp4,fp5 (1*)
fdmul.x fp2,fp7 (2*)
fdmul.x fp0,fp4
fdmul.x fp3,fp6
fdmul.x fp2,fp0
fdmul.x fp3,fp1
move.l a2,-(sp)
fdsub.x fp7,fp5
fdsub.x fp4,fp6
fdsub.x fp1,fp0
fmove.d fp5,(a2)+
fmove.d fp6,(a2)+
fmove.d fp0,(a2)
move.l (sp)+,a2
fmovem (sp)+,fp7/fp6/fp5/fp4/fp3/fp2
rts
it's 4 too, isn't it?
|
The instruction marked (1) and (1*) should be bundled
Same for (2) and (2*)Does this make sense?
We should "prepare" the code to allow the CPU to do 3opp operations
| |
| |
Grom 68k
Posts 61
17 Jul 2019 10:01
| Stefan "Bebbo" Franke wrote:
|
I created a better m68080 automaton definition
_crossproduct:
fdmove.d (a0)+,fp0
fmovem fp2/fp3/fp4/fp5/fp6/fp7,-(sp)
fdmove.d (a0)+,fp1
fdmove.d (a1)+,fp3
fdmove.d (a1)+,fp2
fdmove.d (a0),fp6
fdmove.x fp1,fp5
fdmove.d (a1),fp4
fdmove.x fp6,fp7
fdmul.x fp4,fp5
fdmul.x fp2,fp7
fdmul.x fp0,fp4
fdmul.x fp3,fp6
fdmul.x fp2,fp0
fdmul.x fp3,fp1
move.l a2,-(sp)
fdsub.x fp7,fp5
fdsub.x fp4,fp6
fdsub.x fp1,fp0
fmove.d fp5,(a2)+
fmove.d fp6,(a2)+
fmove.d fp0,(a2)
move.l (sp)+,a2
fmovem (sp)+,fp7/fp6/fp5/fp4/fp3/fp2
rts
it's 4 too, isn't it?
|
Amazing ! (but I count 5 nop) 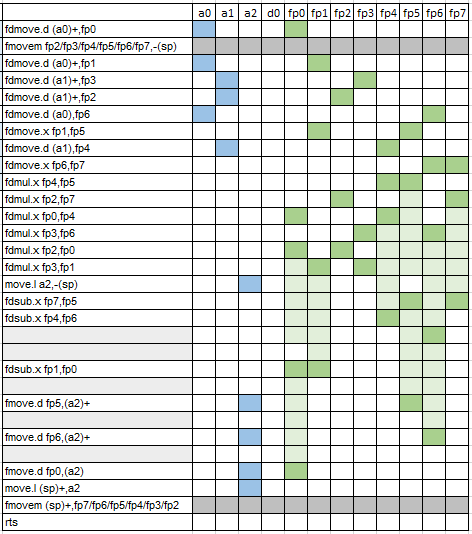
This test case is already dead :)
| |
| |
Samuel Devulder
Posts 248
17 Jul 2019 11:11
| I also count 5 which is much better that 13 or 9_crossproduct:
fdmove.d (a0)+,fp0
fmovem fp2/fp3/fp4/fp5/fp6/fp7,-(sp)
fdmove.d (a0)+,fp1
fdmove.d (a1)+,fp3
fdmove.d (a1)+,fp2
fdmove.d (a0),fp6
fdmove.x fp1,fp5
fdmove.d (a1),fp4
fdmove.x fp6,fp7
fdmul.x fp4,fp5
fdmul.x fp2,fp7
fdmul.x fp0,fp4
fdmul.x fp3,fp6
fdmul.x fp2,fp0
fdmul.x fp3,fp1
move.l a2,-(sp)
fdsub.x fp7,fp5
; 1 (fp6)
fdsub.x fp4,fp6
; 1 (fp1)
fdsub.x fp1,fp0
; 1 (fp5)
fmove.d fp5,(a2)+
; 1 (fp6)
fmove.d fp6,(a2)+
; 1 (fp0)
fmove.d fp0,(a2)
move.l (sp)+,a2
fmovem (sp)+,fp7/fp6/fp5/fp4/fp3/fp2
rts The code coule be better if instead of using a2 we used a0 or a1 (which are dead at this point). The other advantage of using a0 or a1, is that the final fmove.d fp0,(reg) can be delayed after the final fmovem, sparing 1 wait cycle.Anyway, I'll give it a try by hand to see if I can get any better. But I have no real "algorithm", just intuition and symmetry in the computation-tree. However, for quake I've found out that running several computation threads in a diagonal like fashion produces interesting pieces of code where it is easy to spot optimizeable parts... let's see if this strategy is of some help here (more on it later, hopefully).
| |
| |
Gunnar von Boehn
(Apollo Team Member)
Posts 6243
17 Jul 2019 11:47
| Seriouly I doubt this crossproduct is a useful testcase.
The function has not enough math to be useful "unrolled"
FMOVEM registers away to have TMP registers add extra cost and makes only limited sense for such few math operations.
| |
| |
Grom 68k
Posts 61
17 Jul 2019 12:36
| Gunnar von Boehn wrote:
|
Seriouly I doubt this crossproduct is a useful testcase.
The function has not enough math to be useful "unrolled"
FMOVEM registers away to have TMP registers add extra cost and makes only limited sense for such few math operations.
|
I am agree, it was just to show scheduling issues. I have some ideas to optimize unrolling but I am afraid it will be complex. Stefan "Bebbo" Franke wrote:
|
-funroll-loops is working better now too: EXTERNAL LINK |
Is gcc can make difference between subq.l #4,d0 and subq.l #1,d0 ?
If yes, subq.l #4,d0 could be move upward. Is gcc can simplify the step of the loop ?
move.l #640,d0 ;160
.L2:
...
subq.l #4,d0 ;1
jne .L2
I have an other idea but the asm doesn't look like this anymore.
Scale8:
fdmove.x fp1,fp0
move.l #640,d0
fmovem fp2/fp3/fp4,-(sp)
.L2:
fdmove.d (a1)+,fp4
fdmul.x fp0,fp4
fdmove.d (a1)+,fp3
fdmul.x fp0,fp3
fdmove.d (a1)+,fp2
fdmul.x fp0,fp2
fdmove.d (a1)+,fp1
fdmul.x fp0,fp1
fmove.d fp4,(a0)+
fmove.d fp3,(a0)+
fmove.d fp2,(a0)+
fmove.d fp1,(a0)+
subq.l #4,d0
jne .L2
fmovem (sp)+,fp4/fp3/fp2
rts
| |
| |
Samuel Devulder
Posts 248
17 Jul 2019 12:52
| Gunnar von Boehn wrote:
|
Seriouly I doubt this crossproduct is a useful testcase.
The function has not enough math to be useful "unrolled"
FMOVEM registers away to have TMP registers add extra cost and makes only limited sense for such few math operations.
|
Yeah, after a bit of reflection, this cross product doesn't have enough fpu/integer ops to be optimized very much.
It has basically 6 independent products. Great, they can work in parallel and the result of the first two one might arrive "just on time" without any additional delay (or may be 1 wait-state) and the other pairs arrive on time two. But then there are only 3 independent subtraction. This is not enough to cover the delay to wait for the result of the first subtraction. This mean that saving to memory the result of the first subtraction will add at least a 3 cycles delay, meaning that fpu-side this calculation cannot be done with less than 3 or 4 wait-states. Usually we can use these wait-state to deal with integer operations, unfortunately, this codes hasn't any. so I think it is very hard to beat the 4-cycles version suggested above.
Also, as indicated by Gunnar the fmovem load and saves a total of 12 fpu values hence 12 cycles. This is a lot when compared to the wait-cycles. Reducing register usege in that case might be worth it. Here is the solution I came to by hand-optimization_crossproduct:
fmove.d (8,a0),fp0
fmul.d (16,a1),fp0
fmove.d (16,a0),fp1
fmul.d (8,a1),fp1
fmove.d fp4,-(sp)
fmove.d fp3,-(sp)
fmove.d fp2,-(sp)
fmove.d (16,a0),fp2
fmul.d (a1),fp2
fsub.x fp1,fp0
fmove.d (a0),fp3
fmul.d (16,a1),fp3
fmove.d (a0),fp1
fmul.d (8,a1),fp1
fmove.d (8,a0),fp4
fmul.d (a1),fp4
fmove.d fp0,(a2)
fmove.x fp2,fp0
fsub.x fp3,fp0
fmove.d (sp)+,fp2
fmove.d (sp)+,fp3
fsub.x fp4,fp1
fmove.d (sp)+,fp4
;1
fmove.d fp0,(8,a2)
;2
fmove.d fp1,(16,a2)
rts
; total = 29 cycles (include 3 wait cycles) I tried to reduce registers usage (this is possible because "fop reg,reg" is as fast as "fop <ea>,reg") and fill the bubbles in the end of calculation with single fmove.d coming from a split fmovem. I'm usure gcc can split a single fmovem into several fmove.d and move them individually into wait-cycles to reduce total cycle-count.
| |
| |
Stefan "Bebbo" Franke
Posts 142
17 Jul 2019 12:58
| Grom 68k wrote:
|
...
Is gcc can make difference between subq.l #4,d0 and subq.l #1,d0 ?
If yes, subq.l #4,d0 could be move upward.
...
|
since the sub is fused to the jne, there is no gain.
| |
| |
Grom 68k
Posts 61
17 Jul 2019 13:25
| Stefan "Bebbo" Franke wrote:
|
Grom 68k wrote:
|
...
Is gcc can make difference between subq.l #4,d0 and subq.l #1,d0 ?
If yes, subq.l #4,d0 could be move upward.
...
|
since the sub is fused to the jne, there is no gain.
|
Unlike other, #1 is specified for subq/bne fusing. Gunnar von Boehn wrote:
|
MOVEq #,Dn
AND.L Dx,Dn
SUBQ.L #1,Dn
BNE.s LOOP
|
| |
| |
Samuel Devulder
Posts 248
17 Jul 2019 13:45
| ;2
fmove.d fp1,(16,a2)
rts
; total = 29 cycles (include 3 wait cycles) |
Maybe that final bubble can be reduced if we do something like this if the final fmove+jmp operation can be executed together in the same cycle:
move.l (sp)+,a0
; 1
fmove.d fp1,(16,a2)
jmp (a0)
| |
|
|
|


