 Information about the Apollo CPU and FPU. Information about the Apollo CPU and FPU. |
|
|---|
| | 
Gunnar von Boehn
(Apollo Team Member)
Posts 6254
25 Jun 2019 08:33
| Salut Thellier!
In which regard is the created code better?
Maybe I should explain something:
CPU have several options to create a LOOP.
Option a) Using a counter variable.
The counter counts down, and the CPU loops until it reaches the end.
Simple Example code:
while(n) {
*dst++=0x00;
n--;
}
Options how this can be done:
LOOP:
CLR.B (A0)+
DBRA D0,LOOP
or
LOOP:
CLR.B (A0)+
SUBQ.L #1,D0
BNE LOOP
another option is to LOOP until a certain End Address is reached
move.l A0,A1
add.l D0,A1
LOOP:
CLR.B (A0)+
CMPA.L A1,A0
BNE LOOP
Those loops look identical but they are NOT!
Disadvantage number 1:
Register Dependences
Loop A) and B) use independent operations.
The CLR and the DBRA use not the same register.
There are no dependencies.
This means a Super Scalar CPU can execute them in parallel.
This is GOOD.
The 3rd Loop code (C) creates a dependency between the CLR and the CMPA. This means they can NOT be executed in parallel.
This means LOOP code (c) is by design twice as slow!
Disadvantage number 2 - branch prediction.
A CPU has to predict at Branch/Loop instruction
and has to decide predict whether to LOOP or not.
The end of the counting down LOOP instructions is "foreseeable"
A CPU can "SNOOP" the condition of the counter one in advance
and can do such LOOP without misprediction!
This can NOT be done for the LOOP C version.
This means Loop C will get a misprediction penalty of severly clocks.
Many good CPUs like IBM POWER or AC68080 are able to predict the end of a counting down loop correctly and do such Loops without any mis-prediction at all.
To sum this up. Loop construct (c) is for long loop twice as slow,
and for short loops even more than twice slower.
GCC 2.9 was creating Loop (A) code.
New GCC versions seem to prefer Loop (C) code.
The new GCC version seem to be blind to the negative register dependency they created in Loop(c)
and seems to be unaware that CPUs can predict the end of a count down loop - which they kill with using version (c)
Maybe Bebbo has an idea how to fix this?
| |
| | 
Stefan "Bebbo" Franke
Posts 142
25 Jun 2019 09:34
| Gunnar von Boehn wrote:
|
Maybe Bebbo has an idea how to fix this?
|
the current m68k-amigaos-gcc recognizes this as builtin and calls memset.
| |
| |
Gunnar von Boehn
(Apollo Team Member)
Posts 6254
25 Jun 2019 09:50
| Stefan "Bebbo" Franke wrote:
|
Gunnar von Boehn wrote:
|
Maybe Bebbo has an idea how to fix this?
|
the current m68k-amigaos-gcc recognizes this as builtin and calls memset.
|
:-)
Haha nice joke Of course this just an easy to read example which people can follow. The problem we talk about is what LOOP constructs GCC tries to use.
Not just for memset() but in general for all code. GCC 2.9 used often DBRA, which was a good choice. New GCC versions seem to often use "CMPA BNE".
CMPA has the two disadvantages we explained earlier. I dont know why GCC changed this.
Do you have an explain for this? Or more important can we teach GCC to better use do the countdown code like "SUBQ.L #1,D0 BNE" or DBRA?
| |
| |
Gunnar von Boehn
(Apollo Team Member)
Posts 6254
25 Jun 2019 10:06
| For better understanding, lets look at real code:
char strCHECK(char *src,short n)
{
char c =0x0;
while(n) {
c+=*src++;
n--;
}
return c;
}
GCC 6.5b using -Os
_strCHECK:
clr.b d1
add.w a0,d0
.L2:
cmp.w a0,d0
jne .L3
move.b d1,d0
rts
.L3:
add.b (a0)+,d1
jra .L2
GCC 6.5b -O2
_strCHECK:
move.w d0,d1
jeq .L1
clr.b d0
.L3:
add.b (a0)+,d0
subq.w #1,d1
jne .L3
.L1:
rts
The code created with Os is a lot slower and its bigger. :-(
If I change the counter from SHORT to INT then GCC 6.5b
will also for the -O2 compile choose the CMPA LOOP.
I see result like this:
-Os
_strCHECK:
clr.l d1
move.l d0,a1
move.b d1,d0
.L2:
cmp.l d1,a1
jne .L3
rts
.L3:
add.b (a0,d1.l),d0
addq.l #1,d1
jra .L2
or
-O2
_strCHECK:
tst.l d0
jeq .L1
move.l a0,d1
add.l d0,d1
clr.b d0
.L3:
add.b (a0)+,d0
cmp.l a0,d1
jne .L3
.L1:
rts
Bebbo if you look at this you will see the 2 issues
a) the END ADDRESS Calculation makes the code first of all longer!
As this is needed:
move.l a0,d1
add.l d0,d1 And because of the Register dependencies the LOOP will be slower. That GCC used (A0,D1) EA-mode was also not clever.
This mode is longer and slower than (A0)+ on most 68K.
Its pretty slow on 060.
And it add in addition a ALU-2-EA bubble on 060+ Bebbo do you understand why GCC makes these wrong decisions now?
| |
| |
Stefan "Bebbo" Franke
Posts 142
25 Jun 2019 10:31
| Gunnar von Boehn wrote:
|
Stefan "Bebbo" Franke wrote:
|
Gunnar von Boehn wrote:
|
Maybe Bebbo has an idea how to fix this?
|
the current m68k-amigaos-gcc recognizes this as builtin and calls memset.
|
:-)
Haha nice joke
Of course this just an easy to read example which people can follow.
The problem we talk about is what LOOP constructs GCC tries to use.
Not just for memset() but in general for all code.
GCC 2.9 used often DBRA, which was a good choice.
New GCC versions seem to often use "CMPA BNE".
CMPA has the two disadvantages we explained earlier.
I dont know why GCC changed this.
Do you have an explain for this?
Or more important can we teach GCC to better use do the countdown code like "SUBQ.L #1,D0 BNE" or DBRA?
|
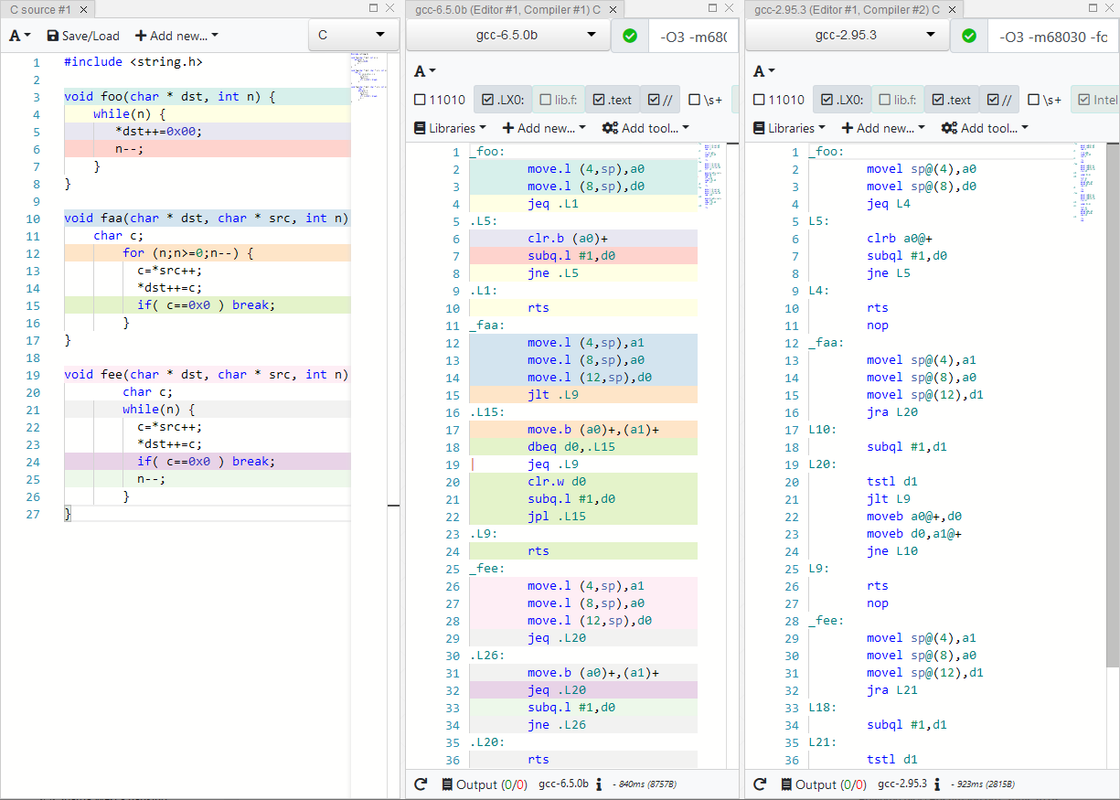
ok - the main cause seems to be -fiv-opts, which is on by default: "Optimizes induction variables in loops." using: m68k-amigaos-gcc -O3 a.c -S -fno-builtin -fno-ivopts yields: _foo:
link.w a5,#0
move.l (8,a5),a0
move.l (12,a5),d0
jeq .L6
.L3:
clr.b (a0)+
subq.l #1,d0
jne .L3
.L6:
unlk a5
rts with my local version. So the cost for using an address registers needs to be higher.
| |
| |
Gunnar von Boehn
(Apollo Team Member)
Posts 6254
25 Jun 2019 10:34
| Bebbo,
Great that you found it!
This loop is so much better now.If you can generally fix this, I can see that some routines will literally run TWICE as fast now.
| |
| |
Stefan "Bebbo" Franke
Posts 142
25 Jun 2019 11:28
| Gunnar von Boehn wrote:
|
Lets look at an example:
void strncopy(char *dst,const char *src,short n)
{
char c;
for (n;n>=0;n--) {
c=*src++;
*dst++=c;
if( c==0x0 ) break;
}
}
|
BTW: that strncpy is buggy and will copy one byte to much
| |
| | 
Thellier Alain
Posts 143
25 Jun 2019 12:31
| >In which regard is the created code better?
I am not an expert but see bellow : it seems there are unnecessary instructions with a for()Compiled with egcs 2.90.27
gcc -Wa,-adhln -g -Wall -m68020-40 -m68881 -noixemul -O3 -c test.c > test-mixed
to generate mixed C & ASM 285:test.c // /*==================================================================*/
286:test.c // void strncopy1(char *dst,const char *src,short n)
287:test.c // {
1345 .stabd 68,0,287
1346 0470 4855 pea a5@
1347 0472 2A4F movel sp,a5
1348 0474 226D 0008 movel a5@(8),a1
1349 0478 206D 000C movel a5@(12),a0
1350 047c 202D 0010 movel a5@(16),d0
1351 0480 3200 movew d0,d1
288:test.c // char c;
1352 .stabd 68,0,288
1353 LBB6:
289:test.c // for (n;n>=0;n--) {
1354 .stabd 68,0,289
1355 0482 6D0A jlt L124
1356 .even
1357 L126:
290:test.c // c=*src++;
1358 .stabd 68,0,290
1359 0484 1018 moveb a0@+,d0
291:test.c // *dst++=c;
1360 .stabd 68,0,291
1361 0486 12C0 moveb d0,a1@+
292:test.c // if( c==0x0 ) break;
1362 .stabd 68,0,292
1363 0488 6704 jeq L124
1364 .stabd 68,0,289
1365 048a 5341 subqw #1,d1
1366 048c 6AF6 jpl L126
1367 L124:
293:test.c // }
294:test.c // }
1368 .stabd 68,0,294
1369 LBE6:
1370 048e 4E5D unlk a5
1371 0490 4E75 rts
1382 Lscope3:
1384 .even
1385 .globl _strncopy2
1386 _strncopy2:
295:test.c // /*==================================================================*/
296:test.c // void strncopy2(char *dst,const char *src,short n)
297:test.c // {
1387 .stabd 68,0,297
1388 0492 4855 pea a5@
1389 0494 2A4F movel sp,a5
1390 0496 226D 0008 movel a5@(8),a1
1391 049a 206D 000C movel a5@(12),a0
1392 049e 202D 0010 movel a5@(16),d0
1393 04a2 3200 movew d0,d1
298:test.c // char c;
1394 .stabd 68,0,298
1395 LBB7:
299:test.c // while(n) {
1396 .stabd 68,0,299
1397 04a4 670E jeq L131
1398 .even
1399 L132:
300:test.c // c=*src++;
1400 .stabd 68,0,300
1401 04a6 1018 moveb a0@+,d0
301:test.c // *dst++=c;
1402 .stabd 68,0,301
1403 04a8 12C0 moveb d0,a1@+
302:test.c // n--;
1404 .stabd 68,0,302
1405 04aa 5341 subqw #1,d1
303:test.c // if( c==0x0 ) break;
1406 .stabd 68,0,303
1407 04ac 4A00 tstb d0
1408 04ae 6704 jeq L131
304:test.c // }
1409 .stabd 68,0,304
1410 04b0 4A41 tstw d1
1411 04b2 66F2 jne L132
1412 L131:
305:test.c // }
1413 .stabd 68,0,305
1414 LBE7:
1415 04b4 4E5D unlk a5
1416 04b6 4E75 rts
1427 Lscope4:
| |
| |
Gunnar von Boehn
(Apollo Team Member)
Posts 6254
25 Jun 2019 13:20
| thellier alain wrote:
|
>In which regard is the created code better?
I am not an expert but see bellow : it seems there are unnecessary instructions with a for()
|
// FOR() CODE
FOR:
moveb a0@+,d0
moveb d0,a1@+
jeq END
subqw #1,d1
jpl FOR
END:
= 5 instructions
// WHILE(n)
WHILE:
moveb a0@+,d0
moveb d0,a1@+
subqw #1,d1
tstb d0
jeq END
tstw d1
jne WHILE
END:
= 7 instructions
Actually in your example the WHILE LOOP is longer. :-(
7 versus 5 instructions
While our "goal" was to have 2 instructions in the LOOP LOOP
MOVE.B (A0)+,(A1)+
dbeq LOOP Maybe more important than GCC 2.9 will be a modern GCC like GGC 6.0
If we can improve 68K code generation on GCC 6, then this would help AMIGA and ATARI a lot.
| |
| |
Thellier Alain
Posts 143
26 Jun 2019 14:45
| >Actually in your example the WHILE LOOP is longer. :-( Houpps you are absolutely right I was too tired the day I posted that :-/
| |
| | 
Michael R
Posts 281
26 Jun 2019 18:12
| thellier alain wrote:
|
char c;
for (n;n>=0;n--) {
c=*src++;
*dst++=c;
if( c==0x0 ) break;
}
writing a loop with C this way generate a better ASM
char c;
while(n) {
c=*src++;
*dst++=c;
if( c==0x0 ) break;
n--;
}
|
Thellier Alain, It's great that gcc is being optimized for Apollo 68080. Also, I have a question about some sample code you wrote called DT2HAM. May I revise parts of it and re-release it?
| |
| |
Thellier Alain
Posts 143
27 Jun 2019 09:09
| Hello Michael Feel free to modify it
EXTERNAL LINK but just release the updated sources too
If you broke compatibility with non 68080 machines then release it as a new package DatatypeToHam was designed for picture quality so it eats lots of memory (not a problem as I used it in WinUAE)
There are several options: if you have a good colors vision (like me) you can see the differences else let default Especially this part eats memory
//allocate a float buffer to store 'errors'
RGBfs= (float *)malloc(HamHigh*HamLarge*3*sizeof(float)); It should better use some kinda "sliding buffer" but not easy to implement ... anyway not a problem on a Vampire Alain
| |
| |
Michael R
Posts 281
27 Jun 2019 11:07
| thellier alain wrote:
|
Hello Michael
Feel free to modify it
EXTERNAL LINK but just release the updated sources too
If you broke compatibility with non 68080 machines then release it as a new package
DatatypeToHam was designed for picture quality so it eats lots of memory (not a problem as I used it in WinUAE)
There are several options: if you have a good colors vision (like me) you can see the differences else let default
Especially this part eats memory
//allocate a float buffer to store 'errors'
RGBfs= (float *)malloc(HamHigh*HamLarge*3*sizeof(float));
It should better use some kinda "sliding buffer" but not easy to implement ... anyway not a problem on a Vampire
Alain
|
Ok. Thank you. I haven't compiled it yet for the 68080. I should do that and test it on my A500 equipped with a Vampire V2. I use AmiDevCpp but I'll try making it with GCC. I made some modifications to your original code in my test program. I compiled it for AROS and it worked. I needed some HAM conversion code for one of my graphics programs for Icaros. I wrote all the ILBM save functions including SaveHAMPic but I needed HAM conversion code. I would have needed to write everything till I found your program. I had some difficulty with the French comments. The main issues were the ILBM header information and it doesn't seem to add padding bytes to the end of scanlines. I'll release the source as well and give credit to you as the original author. I'll compile it for Amiga as well to test on 68080. I saw that you put your name on the Floyd Steinberg function. Is the contact information for you correct. My graphics program is ShowPicture. You can find me as "miker" on Aros-Exec. I'm working on another grahics program converting RayStorm 3D Modeler m68k to work on Icaros Desktop. It would be nice to save rendered images to HAM6 or HAM8 for that as well. Thank you. I'll be using GCC 4.8.3 but if newer versions of GCC are being optimized for 68080 I'll try that too.
| |
| |
Stefan "Bebbo" Franke
Posts 142
29 Jun 2019 06:12
| Ok, I made some changes which are now live:
EXTERNAL LINK
| |
| |
Stefan "Bebbo" Franke
Posts 142
29 Jun 2019 08:37
| Gunnar von Boehn wrote:
|
Patching GNU ASM is easy.
We added support for APOLLO instructions to it already.
|
And I'm still looking for that GNU ASM patch...
| |
| |
Stefan "Bebbo" Franke
Posts 142
29 Jun 2019 08:41
| thellier alain wrote:
|
>Actually in your example the WHILE LOOP is longer. :-(
Houpps you are absolutely right I was too tired the day I posted that :-/
|
the while loop is stoll longer with my recent changes, now it's
for: 3.000045 instructions
while: 4 instructions
| |
| |
Gunnar von Boehn
(Apollo Team Member)
Posts 6254
29 Jun 2019 08:47
| Stefan "Bebbo" Franke wrote:
|
Ok, I made some changes which are now live: |
Great work Bebbo! I think this improves significantly loop code generation for 68K family. Bebbo, regarding the GCC FPU code generation.
Will teaching GCC to use little bit more parallelism on FPU instruction take you long?
Can you make a short C code example showing the effect/difference? "Vielen Dank" in advance
| |
| |
Gunnar von Boehn
(Apollo Team Member)
Posts 6254
29 Jun 2019 09:44
| Stefan "Bebbo" Franke wrote:
|
Gunnar von Boehn wrote:
|
Patching GNU ASM is easy.
We added support for APOLLO instructions to it already.
|
And I'm still looking for that GNU ASM patch...
|
Bebbo, the batch is not complete.
Its only some of the normal instructions like: "TOUCH" or "ADDIW.L" or "HINT".
More work would be needed to enable e.g the more register.
| |
| |
Stefan "Bebbo" Franke
Posts 142
29 Jun 2019 09:53
| Gunnar von Boehn wrote:
|
Stefan "Bebbo" Franke wrote:
|
Ok, I made some changes which are now live:
|
Great work Bebbo!
I think this improves significantly loop code generation for 68K family.
Bebbo, regarding the GCC FPU code generation.
Will teaching GCC to use little bit more parallelism on FPU instruction take you long?
Can you make a short C code example showing the effect/difference?
"Vielen Dank" in advance
|
First I need more information about all of this. Which cpu - of the ones implemented in gcc - is the closest match and a good starting point? Some cold fire? one of i386? mips? sparc? ...?
| |
| |
Stefan "Bebbo" Franke
Posts 142
29 Jun 2019 09:56
| Gunnar von Boehn wrote:
|
Stefan "Bebbo" Franke wrote:
|
Gunnar von Boehn wrote:
|
Patching GNU ASM is easy.
We added support for APOLLO instructions to it already.
|
And I'm still looking for that GNU ASM patch...
|
Bebbo, the batch is not complete.
Its only some of the normal instructions like: "TOUCH" or "ADDIW.L" or "HINT".
More work would be needed to enable e.g the more register.
|
A start is a start - is a start - is a ... Why not fork my binutils-gdb and provide a pull request? That way I can tell gcc to use those insns too and maybe extend objdump to disassemble these insns correctly. Or mail me a patch or the patched files or ... :-)
| |
|
|
|


