|
|---|
| | 
Jim Drew
Learn who I am!
Posts 67/ 1
11 Nov 2019 19:14
| Vojin Vidanovic wrote:
|
Get on irc with team, be a pro vamp developer.
|
I was at one point. I had my own FTP directory even. I was kicked off because I work with MikeJ on the Replay (and now Replay2) project. I am also working with other FPGA developers on their projects as well. There are a lot of systems running various FPGA based Amiga emulators now.
| |
| | 
Samuel Devulder
Posts 248
11 Nov 2019 20:35
| Jim Drew wrote:
|
That would be great if the Mac's video buffer was some nice normal RGB type configuration. It is only in 8 bit (256 color) mode. The 15/15/24/32 bit modes all use Apple's bitmap color ordering.
|
Is that
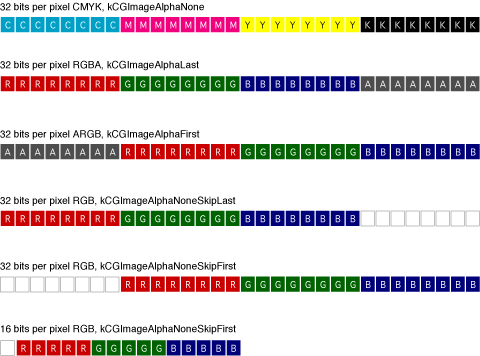 ? ?
(source: apple developper guide EXTERNAL LINK ).
In that case, they match what SAGA can do with RGB (I don't know for CYMK, though).
| |
| |
Jim Drew
Learn who I am!
Posts 67/ 1
11 Nov 2019 21:28
| The Mac uses RGB15 and ARGB32 for "thousands" and "millions" modes, respectively. If Picasso96 reports these modes as being available, then I can use them from within a video driver. Most of the graphics cards for the Amiga were based on PC video card chips, which were all BGR for the 15 bit and higher modes. Which is why a refresh is required.
| |
| | 
Gunnar von Boehn
(Apollo Team Member)
Posts 6254
12 Nov 2019 08:30
| Jim Drew wrote:
|
I was at one point. I had my own FTP directory even. I was kicked off because I work with MikeJ on the Replay (and now Replay2) project. |
Again this is not true.
| |
| | 
Vojin Vidanovic
(Needs Verification)
Posts 1916/ 1
12 Nov 2019 10:28
| More important, can Jim qualify as developer and get driver source access for sale of implementing improved video to fusion
| |
| |
Samuel Devulder
Posts 248
12 Nov 2019 11:21
| ( oops, wrong handling. Ignore this msg. ;) )
| |
| |
Jim Drew
Learn who I am!
Posts 67/ 1
12 Nov 2019 16:32
| Gunnar von Boehn wrote:
|
Jim Drew wrote:
|
I was at one point. I had my own FTP directory even. I was kicked off because I work with MikeJ on the Replay (and now Replay2) project. |
Again this is not true.
|
Perhaps you care to explain why you did then? I keep all of the my emails and IRC chat session logs. :)
| |
| |
Vojin Vidanovic
(Needs Verification)
Posts 1916/ 1
12 Nov 2019 18:37
| Please, gents. Question is what can be done now, not what happened in past
| |
| |
Jim Drew
Learn who I am!
Posts 67/ 1
12 Nov 2019 22:22
| Vojin Vidanovic wrote:
|
Please, gents.
Question is what can be done now, not what happened in past
|
Answer: if the SAGA .card driver has all of the support necessary, then the existing Picasso96 software should work as-is, supporting everything from direct frame buffer access to blitter speed ups. I have not looked at the GOLD series core because there was a problem with the RsrvMem setup that the Vampire installs. I would need to write a new RsrvMem program that deliberately rebooted the machine and got rid of what the Vampire does on it's initialization. It is causing problems with the operation of FUSION. I think it was VBR related or something like that. I don't recall as it was awhile ago (when GOLD was released). The Amiga and Mac have to share the first 8K of CHIP memory, and the Mac has priority over it.
If there is support missing then I could can make a video driver for FUSION (and PCx) like I did for all of the original video cards (Picassso II/IV, Retina, RetinaIV, PiccoloSD64, Cybervision64, etc. etc.) I do have the source code for a skeleton .card driver for Picasso96 that Alex and Tobias gave to me back in the day because Utilities Unlimited was working on a video card for the Amiga. There are some private vectors in the PicassoAPI for doing things Mac related, and the .card driver has to support those things or I have to make a completely new driver.
With no direct video, and no MMU, FUSION and PCx emulations suffer greatly in performance! Mikej is adding window comparators for me to Replay/Replay2, which will let me emulate a single entry MMU. I can use these comparator windows to greatly speed up various emulation parts where I have to check (at a minimum of every vertical blank) to see if something (emulated hardware) has changed states.
Having complete Picasso96 support in the SAGA .card driver would increase compatibility and speed of everything that used RTG.
| |
| |
Vojin Vidanovic
(Needs Verification)
Posts 1916/ 1
12 Nov 2019 23:20
| Current v2/v4 support RTG P96 PiP.
Improved video driver would be a feature worth of new number, and payement/purchase.
Team can let you know of Vamp reserved spaces and addresses.
You could try mapping MMU calls to PMMU just for Fusion/PCx needs.
A bit like in early CBM and community days. Find the way :)
Smoke and Soul Belgrade EXTERNAL LINK RTG
https://wiki.apollo-accelerators.com/doku.php/system_tools:rtg
SAGA
https://wiki.apollo-accelerators.com/doku.php/saga:video
| |
| |
Jim Drew
Learn who I am!
Posts 67/ 1
14 Nov 2019 00:32
| Thanks for the info. I guess will have to update my Vampire 2 to the latest core and look at what the SAGA driver returns for video modes and private vectors.
| |
| |
Vojin Vidanovic
(Needs Verification)
Posts 1916/ 1
14 Nov 2019 13:28
| Jim Drew wrote:
|
Thanks for the info. I guess will have to update my Vampire 2 to the latest core and look at what the SAGA driver returns for video modes and private vectors.
|
Bon voyage, and think of v2 version with lower precision FPU and v4 branch with usage of full FPU. v4 is now standalone only, but in future there will be v4 cards for Classics.
| |
| | 
Don Adan
Posts 38
14 Nov 2019 18:44
| Gunnar von Boehn wrote:
|
Markus B wrote:
|
And for the x86->68k conversion: I would imagine this as something like a hardware assisted JIT compiler, right?
|
Let me try to explain my thoughts more clearly.
Lets first clarify some namings:
What means "Emulation"?
Emulation means being able to execute programs meant for another CPU on your CPU.
For example running a C64 program for the C64-6510 CPU on your 68000 CPU.
A program is constructed by many instruction.
The emulation will "replace/emulate" them one by one.
There are 2 common type of how to "emulate" another CPU.
A) Interpretive
B) JIT
Interpretive Emulation will instruction per instruction first "detect with foreign" instruction the next instruction is,
and then execute some native instructions to "emulate" the behavior.
Cost = Detection + Emulated-Execution
Typical Cost for each foreign opcode is roughly
30 instruction clocks for detection
+ 1-10 instructions for execution.
The drawback for Interpreter execution is that again and again the "Detection" cost is paid.
JIT will detect and save new code,
this new code includes only the "Emulation-Instruction"
Cost for JIT is roughly 400 cycle for detection and code creation,
but for execution only 1-10 instructions.
Lets make a simple example
Lets say there is an x86 workloop of 3 instructions which gets executed 100 times.
Lets say the average Emulation cost per instruction is 6
Interpretation Cost
100 * (30+6) == 3600 clocks
JIT Cost
400 + 100 *6 == 1000 clocks
You can clearly see for LOOP code.
JIT will become MUCH faster.
And all major work in programs is done in loops.
Now what the bottleneck for JIT performance?
The answer is the Execution Cost per instruction.
The Execution Cost per Instruction is influenced by the "capabilities" of the CPU.
If the foreign CPU can do stuff that our own CPU can NOT do with own instructions then emulating can not be done with 1by1 instruction but maybe we need 5 instruction or 10 instructions to do the work of the foreign CPU.
This is pretty obvious and logical.
Lets sum this up.
1) A JIT emulator will give better speed than Interpreters.
2) if our own CPU can natively do all "tricks" the foreign to be emulated CPU can do - then its easier and cheaper to emulate it.
From a CPU HW point of view this means.
If the x86 can do some "tricks" which the 68k can native not.
We can make emulation easier by adding those tricks to the feature list of the core.
All clear now?
Lets get back to our example:
Interpretation Cost
100 * (30+6) == 3600 clocks
JIT Cost
400 + 100 *6 == 1000 clocks
Lets say we add more "tricks" and improve our cost ratio lets say from 6 to 2
This means our new cost will be
JIT Cost
400 + 100 *2 == 600 clocks
|
Sorry, but for me this is not easy to make good JIT x86 for 68k. How you want to detect x86 opcode, data or text? Without good x86 code detection, every byte of program will be called as code. Next problem is to detect and handle self modyfying code (if SMC is possible on x86). Some years ago I started to create JIT converter (for 68k) for SPC700 CPU, code detection and SMC detection is not very easy. For me easy enough and realistic for normal emulation of LE CPU's with 68080 will be only adding one extra instruction mover.w/mover.l (CCR unchanged) to the core. Move reverse can replaced up to 6 (?) 68k instructions when LE longword is readed from memory
Move CCR,d7 ; backup ccr
Move.l
Ror.w #8
Swap
Ror.w #8
Move d7,CCR, ; restore ccr Maybe even mover.q can be used for something.
For PCx very useful can be x86 to 68k code/exe converter or even source converter only. If PCx will be able to detect and convert all x86 code used by program to 68k in init part, then will be super fast. But this is not easy job.
| |
| |
Gunnar von Boehn
(Apollo Team Member)
Posts 6254
14 Nov 2019 19:34
| Don Adan wrote:
|
For me easy enough and realistic for normal emulation of LE CPU's with 68080 will be only adding one extra instruction mover.w/mover.l (CCR unchanged) to the core. Move reverse can replaced up to 6 (?) 68k instructions when LE longword is readed from memory
Move CCR,d7 ; backup ccr
Move.l
Ror.w #8
Swap
Ror.w #8
Move d7,CCR, ; restore ccr
|
68080 does already have such Endian-Reverse MOVE instruction.
Its called MOVEX
| |
| |
Jim Drew
Learn who I am!
Posts 67/ 1
15 Nov 2019 16:32
| I don't have to worry about the CCR because flags are handled differently, but there is no difference in speed between the long form version using ror/swap and the single movex. Apparently, the pipeline/cache absorbs the multi-instructions, or there is a stall with movex. In either case, I saw no difference in speed. This is one of the first things I had implemented into PCx. If this was improved since the mid-Silver core series, I can take a look again.
| |
| |
Vojin Vidanovic
(Needs Verification)
Posts 1916/ 1
15 Nov 2019 20:02
|
v600 cores
https://wiki.apollo-accelerators.com/doku.php/vampire:v600-v2:updates
| |
| |
Don Adan
Posts 38
16 Nov 2019 01:16
| Jim Drew wrote:
|
I don't have to worry about the CCR because flags are handled differently, but there is no difference in speed between the long form version using ror/swap and the single movex. Apparently, the pipeline/cache absorbs the multi-instructions, or there is a stall with movex. In either case, I saw no difference in speed. This is one of the first things I had implemented into PCx. If this was improved since the mid-Silver core series, I can take a look again.
|
Strange for me movex.l version must be fastest, or this instruction works slowest than normal move.l.
Then only full conversion from PC exe to Amiga exe format can give maximum speed for PCx. But it needs many works.
| |
| |
Samuel Devulder
Posts 248
16 Nov 2019 09:02
| Jim Drew wrote:
|
Apparently, the pipeline/cache absorbs the multi-instructions, or there is a stall with movex.
|
Or loading/storing 32bits from/to memory isn't the most frequent opcode in the tested x86 program, or there are other parts of the emulation that consumes a significant portion of the cpu-power so that gaining a few cycles on byte swapping isn't visible. There are many possibilities. Do you have a kind of profiler to detect which part of the emulation consume most of the cpu resource? That could be handy to specifically target optimization on these parts.
| |
| |
Jim Drew
Learn who I am!
Posts 67/ 1
18 Nov 2019 05:14
| Samuel Devulder wrote:
|
Or loading/storing 32bits from/to memory isn't the most frequent opcode in the tested x86 program, or there are other parts of the emulation that consumes a significant portion of the cpu-power so that gaining a few cycles on byte swapping isn't visible. There are many possibilities. Do you have a kind of profiler to detect which part of the emulation consume most of the cpu resource? That could be handy to specifically target optimization on these parts.
|
No, I don't for PCx (I did do this for FUSION-PC when I wrote the 68K CPU core in x86 assembly for the PC). WORDS are the most common fetch/store (which have to be rotated) that are used. I believe there is a movex.w that does the fetch and rotate at the same time with a word. move.w/ror.w uses the same amount of time. The instruction decoding fetches the instruction (word wide) and does a lookup for the opcode decoding, and most instructions will fetch another word. I have tried various methods, like fetching the longword and using the low word as the index. I spent months testing various combinations. Some cases were faster than others of course, but I ended up settling for what was the best overall average for speed. Keep in mind that PCx is 1.7 million lines of hand optimized (and unrolled) assembly code, so it is quite a task to make changes without breaking something! Register usage is very tied to sequential decoding operations.
Pipelined (dual executed) instruction collisions don't occur much because I already kept this in mind for the 060, however, I did also test using the extended (E) registers that the Apollo core has and that also didn't result in any difference in speed. Like I said before, if Gunnar has made optimizations since the mid-Silver series core then I could try testing some things again.Is the V4 actually available? Is it any faster or have other features that don't exist on the Vampire 2 boards?
| |
| | 
Markus B
Posts 209
18 Nov 2019 07:34
| To my knowledge, the FPU in the V4 is full featured and compatible.
| |
|


